 August 23rd, 2023
Multi-region progress ;)
By Jeffrey M. Barber
August 23rd, 2023
Multi-region progress ;)
By Jeffrey M. Barber
I’ve made some progress in getting multi-region closer to a finish line. At this stage, the primary value proposition of multi-region is reducing latency by putting machines closer to people. There are future stages which I’ll touch on briefly like availability and surviving disasters, but those are out of scope. (Honestly, multi-region should be out of scope).
I’ve talked in the past about multi-region aspects here and here. At core, it’s hard as I started with a single database design. When I tried to use a global database, I found performance to be lacking for many reasons. First, my transactions are not lean and there are many back and forth conversations which I haven’t prioritized fixing. Second, I have database calls inside event threads which is problematic for oh so many reasons.
Fixing everything, I’ve been abstracting everything away behind asynchronous interfaces. My mistake early on was “just talk to the database” which helped me move fast in defining the product, but it has been hurting me as I think more about performance and multi-region. I knew I was making a mistake, and now I’m paying the price.
The performance reasons alone are justification to cleaning things up, but the gist is that I’m turning things like
Domain domain = Domains.get(nexus.database, host);
into
domainFinder.find(host, new Callback<Domain>() { ... });
It’s especially obnoxious that I’m doing this when Java’s virtual threads are becoming a thing, but I’ve grown accustom to managing executors and callbacks without much fuss. As such, I’ve almost got everything converted to the new way, and then I’ll play with load testing to isolate calls to a cached executor such that the main thread is primarily compute. The way this helps with multi-region is that I can turn one region into a global region. The local regions all talk to the global region as a control plane using the existing web socket server.
For example, authentication is a fine reason to cross the regional boundary. This also helps me control my secrets distribution as I can put local regions in more environments as they will not have any secrets.
However, the data plane is where products run; as such, this is where I am focusing focus on making the most of the local region. The practical side-effect is that establishing a connection is slow while interacting with a product is blazing fast.
We can give the pattern a picture as thusly:
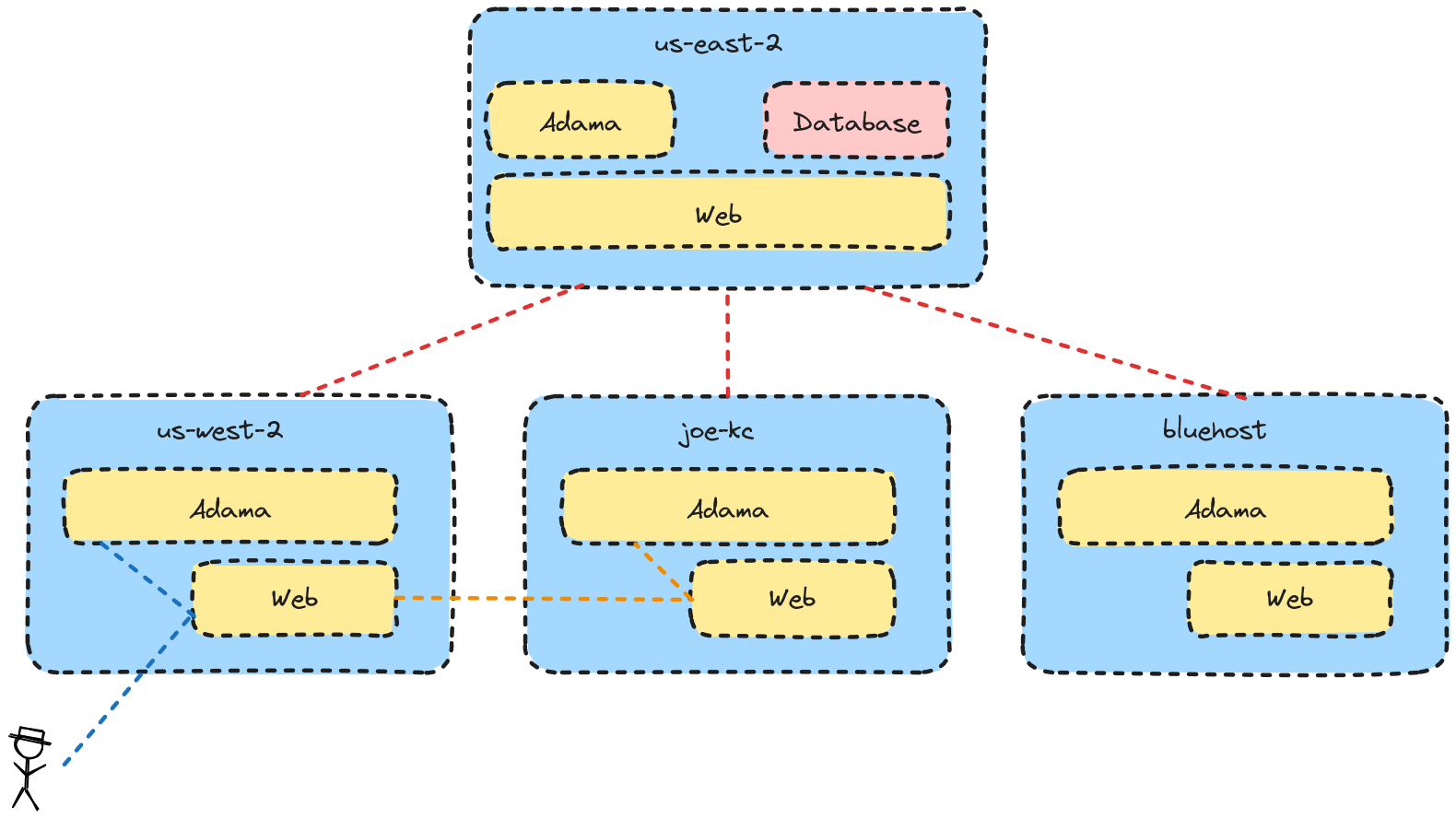
From an user experience perspective, everything that is control plane related flows to the global region. So, this is authentication, messing with authorities, deployments, etc. Connecting to a document is where things get interesting as documents are regionally homed. For example, if you connect to a document that is in the archived, then it will be restored within your local region. Thus, you’ll have like 5 milliseconds for read and write operations which is fantastic!
However, If you connect to a document that is loaded within a remote region, then your latency is the sum of the latency to your local region plus the latency between the local region and the remote region. This is a consequence of the design, but it is also practical since experiences generally are localized in many ways. Practically, this means the documents are going to biased to the first person to load them which is great for local businesses.
That’s the V1 launch plan for multi-region support, so let’s talk about a few random things.
First, an availability hit to the global region is going to cause problems. However, the local region is going to maintain a cache such that documents loaded within a region are going to stay within that region. However, documents that are archived or new will be unavailable. This is because the global control plane has the responsibility of providing a compare and set transaction for which machine and region owns the document (eventually, it will be which regional cluster owns the document where a cluster uses raft to durability execute transactions). Everything else could use a global data store with time-based conflict resolution (or write once).
Second, the work to “async-ify” all the contracts are prime opportunities to introduce cache policies which further mitigate and lesson the impact of an availability crisis. Something that is worth considering is sorting out how to replicate data from the global region to a local region such that much of the control plane is self sufficient to a region beyond writes. For much of the control plane, I’m fine with the availability of writes going down while reads work. However, this requires more cost which isn’t on the menu at the time, but as I review the various touchpoints between the region and the control plane it will require a tremendous effort which justifies investing in a database that already provides regional replication.
Third, it was useful to leverage a database to build and iterate on the product specification, but now I’m debating using a more edge-friendly database product rather than re-invent everything. The advantage of my current plans and shipping V1 multi-region is that I’ve cleaned up the critical contracts which will enable a more piecemeal migration towards a better world.
All this is extremely exciting stuff especially once I have a region within my city and experiences are blazing fast.