March 6th, 2022 Next steps post early access launch By Jeffrey M. Barber
So, I launched and the next steps should be to go solicit people, hone my messaging, and try to get adoption. Fortunately, I have a few users, so my #1 priority it to support them. Unfortunately, I’m too embarrassed about the current of state of things and intend to focus on key technical limits. The key limit right now is the inability to scale up, and I’m perfectly happy to scale up without paying customers. Since I’m the largest customer of this infrastructure, I have to be happy.
High level user feedback
I got great feedback which is underpinned by me being cursed with knowledge. I had a bug in the tutorial’s code, and while that was embarrassing. It revealed the sad state of telling users of the jar what is happening. A random error code and a useless stack trace are not helpful. The good news is that each exception source has a unique error code. The bad news is that code is useful to only those that are willing to cross reference with the open source repo. So, now I have the glorious task of tagging each error code with useful meta data like a description which I’ve started. I’m using annotations to tag each one, and then a bit of code generated wizardry to build up a more useful error table.
Deep technical issues
There were two punches to the face. First, the latency between Adama and RDS leave a lot of room to grow. Problematically, even if I optimize things 10x or 100x then it will still not be awesome. Instead, I’m going to radically simplify how I think about data. The second punch to the face was the gRPC traffic between the web host and the Adama host was exceptionally CPU heavy with lots of queues bouncing around. And yet, the CPU required for handling the client’s traffic barely registered. I’d like to replace gRPC with just netty since I’m not really using any gRPC features. I’ve already written a simple wrapper around netty and my own codec code generator. As a spiritual ideal, I’d like to remove gRPC from the stack to further shrink the JAR size.
Clearly, progress is being made on nuking gRPC (at least for web to Adama).
Paradoxically, there is a reason I’m working on the #2 priority since I’ve been thinking about how to approach the data side. We can start with the ideal that an Adama host owns a document. As this is a hard guarantee, we currently rely on the data service to perform an atomic append to pick a winner when two Adama hosts emit data. I’m thinking of radically simplifying my approach. The critical motivation is that scaling out requires a level of indirection, and I’m considering building a locator service.
This location service would require a method like:
public void getDataTarget(
Key key,
Callback<String> callback);
This method would tell the caller which host does the key belong to. We then forward requests to that host. Using a cache and dealing with temporal inconsistency will require the associated service to reject requests that don’t work. Such a proxy service would allow me to scale out RDS horizontally, but this then begs an important question: how do I migrate data between RDS instances.
Migration is tricky because ideally you want to do it outside of the main request path and be invisible to users. Problematically, this requires some kind of agent to drive the migration. However, thinking about this relates to an open issue which I believe is interesting to address. These state machines are tricky as you ideally want to seamless transfer data while a user is using a document without introducing failures.
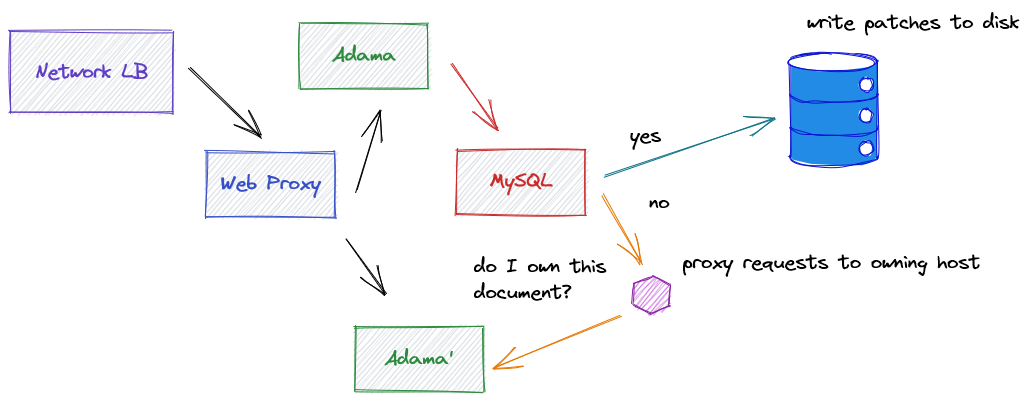
Migrating data out of RDS does require yet another transaction, but I’m thinking of nuking RDS entirely for latency. I have a few hacks in Adama to measure different ideas. You can prefix keys with “mem_” to use an in-memory data service and “disk_” to use a very simple disk backed data service. These gave dreamy latency numbers. Clearly, the “mem_” prefix is not for customers, but if I commit to using EBS then I could make simple disked back data service work with the proxy service.
Here, I’d use the disks on Adama’s machines for storage of logs. Adama will cache the getDataTarget results and if it is the winning host for the data, then it will hold onto that forever. Only that host with the log could call the write function in the locator service.
public void mapDataTarget(
Key key,
String target,
Callback<Void> callback);
## Simple things can have deep problems This scheme has obvious problems, so let’ grind through how to think about various aspects.
| aspect | result |
|---|---|
| availability | Subject to host availability. A data center outage would cause 20%+ drop. This is bad. |
| durability | Subject to EBS at around 99% |
| latency | Fantastic! During peace times, no off-box hops are required. |
| reliability | Fantastic! (for documents that are available during peace times). |
Currently, I’m not using Multi-AZ RDS, so the above mirrors what I’m currently getting with RDS. If I treat the Adama hosts with respect, then building my own disk backed logger may be a decent option. I should be mindful of corruption, and think longer term about the records I lay on disk. So, there will be an effort to make it reasonably efficient and correct. However, I’m not digging the durability, and I also don’t want to manage Adama hosts with long term storage given I fully expect a host to die in the future.
Fortunately, our good old friend called Pareto whispers in our ear that not all documents will be accessed all the time. I could guess that 90% of the data will be cold, so migrate it to something like S3. If S3 was a special target returned by the locator service, then any Adama could pull logs from S3, take ownership, then archive them back once done. Making this archiving an active process means our backup mechanism is constantly being leverage as a main-line feature.
Introducing S3 only changes the long term durability and brings up the average where the last 10 minutes have 99% durability and everything before then is 99.9999%. This would result in a daily durability of 99.99% (10 minutes * 0.99 + 1430 minutes * 0.999999) / 1440 minutes. Availability would improve for documents being loaded from archives, but current customers would suffer. It’s not perfect, but it’s also not shabby. I also have no issues with front-loading latency on the first-connect side.
In terms of capacity management, the proxy aspect would allow unchecked growth. However, capacity removal requires exceptional care as the hosts being removed required a hard drain. Given all the thinky thought details emerging, a more thorough design document may be needed to formalize.
Improving the durability requires some thought which is where I’m thinking about master-master replication.
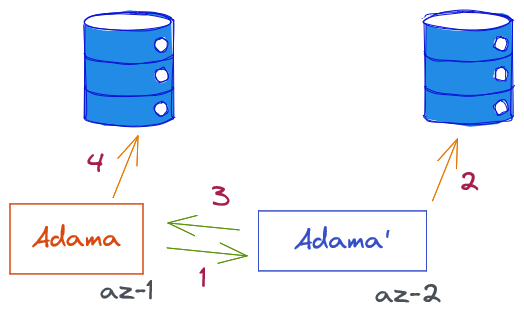
Here, a document would map to two hosts. These hosts would be striped across two availability zones. Ideally, the primary (red) Adama would produce changes, (1) send them to the secondary master, (2) the secondary master integrates and commits, (3) responds to primary master, (4) primary master writes change to disk. The second master could accept traffic as well, but it will (3) forward the request to the primary which will execute the prior flow. The important aspect is that an acknowledgement to the customer requires two machines, and this only introduces one hop during times of peace.
We really have to consider one key scenario: Adama and Adama’ become disconnected for too long. Either there is a network partition or a host died. The worse case is when a partition happens and both Adama instances are running and think they should be primary. Regardless of how it happened, it requires an external party to decide things which is where the locator service would have to pick a winner using a consensus algorithm like Raft.
Each of them will ask the locator service for a new host to replicate to, and then they will start the replication of active documents. Once an active document is replicated, a request is sent to the locator service to confirm it. This will establish the primacy of the winner. Alternatively, the loss of a pairing could signal motivation to archive the current results to S3 and then abort serving the document. It may make a great deal of sense to simply rely on S3 as the primary store, and then optimize the most recent activity to lower costs.
Using what you have
Another thought that I have is how to bring the web proxy hosts into the picture. If the goal is to be a low-latency write ahead logger fronting S3, then could I achieve better durability by persisting data changes up to the client to hold onto for a later reconstruction. This is complicated, but it becomes an interesting possibility with the streaming protocol. The key failure mode is the simultaneous death of a web node and an Adama node.
…
For now, these are fanciful thoughts, but I’m trying to minimize cost, minimize latency, accept higher connect latency, maximize durability, lower storage cost, and achieve availability to maximize sleep. Wish me luck!