February 17th, 2022 Deep Thoughts on Developing a Distributed Stream Query Language from the Ground Up By Jeffrey M. Barber
As I type up my notes on the problems facing Adama, I’m thinking of how to integrate Adama within existing environments. A key problem for Adama’s future is that data held within Adama is currently very siloed. For board games and collaborative applications, this is perfectly fine. However, this can become problematic for many reasons. This is especially important for tactically migrating anything to Adama since developers need some degree of moving applications via a half-state.
The first integration problem I have is getting data out of Adama and into other data-sources which can be queried alongside other data. This breaks the silo aspect from a read-only perspective. The key is that I can leverage the fact that Adama has a state machine model, and I can put foreign replication within that state machine model.
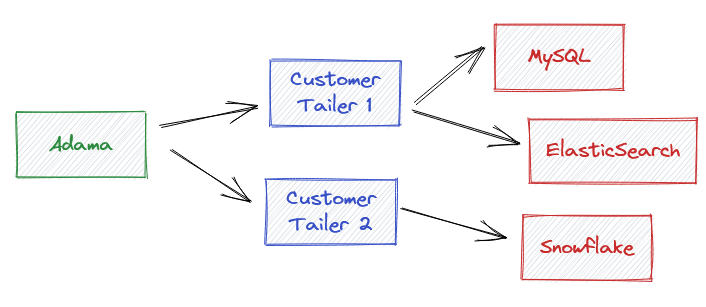
Here, I’ll stuff “web hook style endpoints” either in the Adama code or the deployment script. The distributed system will then track replication of Adama’s state for the multitude of customer endpoints. Of course, this will leverage streaming for a few reasons:
- This gives customers the opportunity to react to only data changes rather than shredding the document excessively. This saves resources when compared to a request response web hook at the expense of memory.
- This allows flow control between Adama and the customer’s tailer to operate such that the customer’s tailer is not overwhelmed with needless updates on a per document basis.
- By having a replication model rather than a notification model, customer’s have reliable knowledge that everything within Adama has been replicated. And, should things be going poorly, we can track the replication delay and find problematic documents which fail to replicate (i.e. poison logic within Customer’s tailer). Web hooks tend towards loss as the producer must give up while a state machine can just sit there with a white flag (and white flags can be counted).
Furthermore, by embracing multiple customer tailers, this creates the opportunity for customers to recover when their tailers have problems. They can simply rebuild their indices because they can copy everything out of Adama by introducing a new tailer.
Given Adama’s privacy model, each tailer would have a credential, and the tailers would be reactively respectful of sensitive information. For example, if Adama was used to store phone numbers, then indexing by phone number would only be available if the owner of the document allows the credential to see the phone number. This is some next-level privacy sensitive infrastructure.
This is a neat way to get data out of Adama, and I’ll think about how it fits within the strategic prioritization of future things to be done.
Unfortunately, I feel sad that I’m taking data out of Adama and putting into non-streaming data stores. Adama is pretty cool, so now I’m wondering what would a streaming query language look like.
Reactive Document Query Language
So, we start with an observation that everything is a document.
- JSON is clearly a document format
- A single variable is the meat inside a document, so it’s document-adjacent
- A giant table held within a DBMS is a document with a rigid structure
- The result of executing an SQL query is also a document
Everything is a document!
The reason I call out this obvious fact is that we need symmetry to bring things together within a query language. I need things to have the same shape, so they can be asked questions, transformed, reduced, merged, etc.
The next step is to build an algebra over the documents which answers questions like:
- How do I pull data out of documents into a smaller document
- How do I combine data from multiple documents into a document
- How do I reduce data within a document to a smaller document
It’s a straightforward task to go off and build a language to take data and turn it into smaller data which is what humans need. Humans need small but important insights from large datasets. I’ll not go deep into the weeds of the algebra, but what I’m confident in saying there is a progression of thought.
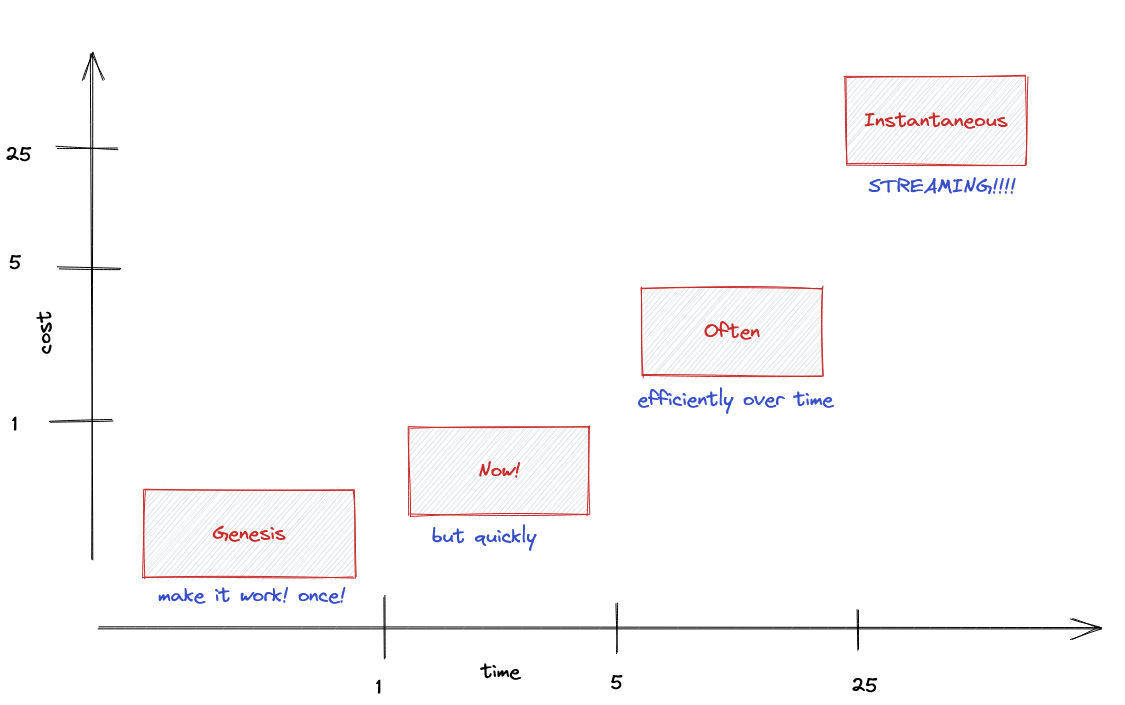
We start with the idea where you get excited, grab a parser, and get crack’n. You’ll play this game of defining what your layout (i.e. data interface) is, build operations that go off and find data and conform it to your layout. Then, you’ll define operations that take your layout with some parameters or logic to turn it into different data that conforms to your layout. As an example, SQL turns tables into tables.
Like many engineering projects, it’s easy and cheap to get started with some good’ole hacking. However, time marches on and demands increase. How dare those pesky users have demands! The first demand relates to the fact that your ad-hoc language is going to be slow, so you start looking at user behavior and finding ways to optimize their queries. This starts an infinite game requiring optimizations that persist between queries like indices, and this further advises how to optimize queries. Then, those damn users, start to poll queries all the gaud damn time, and then you realize that maybe an event sourcing model would help.
This is where you will note that the scales on the above graph are logarithmic which reflects the realities of engineering especially when initial plans are half-baked, and most plans are half-baked at best.
Streaming is all the rage because reality is real-time, and people want to react (or at least feel reactive) to recent events. This all depends on the context, but having your data update quickly is amazing. Unfortunately, streaming is expensive, however there are gains as polling at infinitesimal frequencies has infinite cost. The faster you want data, the more expensive it will be, and streaming becomes the only way to reduce the cost.
Unfortunately, the cost of streaming requires us to burn gray matter instead of coal since this an area of active research. Streaming is hard, and I recommend reading Why query planning for streaming systems is hard by Jamie Brandon
My opinion on this from my career is to start with code first, and then let the language emerge. In the case of BladeRunner, which is the streaming system I architected, it used JavaScript to pull streams together into a reasonable stream for products. This was hard, but it revealed to me the nature of streaming. A key problem is that streams of data mutations will overload humans and systems, there is simply too much data churn. The day one problem to focus on is flow control and how it relates to latency.
My thinky thoughts on this
First, I need a data interface, and I’ll use Adama’s model of a reactive document. Here, I utilize a connection between the producer (Adama Server) and the consumer (Browsers) such that initial connection yields the privacy checked document once and then updates are sent on all changes. These changes leverage algebra to handle congestion, and I believe using algebraic flow control is an important aspect of the streaming problem. The lack of algebra, in my opinion, makes pub-sub and event sourcing awful.
Since my bias is to start with code, the first problem to address is how do I bring external data into an Adama document.
// the address of the remote document
private string space;
private string key;
// figure out how to load a schema in from the outside
@schema remoteSchemaName "the_file_outlining_schema.adama";
// link a document of the schema type to a real
// document located at (space, key) under the local name doc.
foreign<who> remoteSchemaName<space, key> doc;
This would establish a singleton link between the current document and a remote document, and this can be put into multiplicity by making the foreign keyword work within a record.
// figure out how to load a schema in from the outside
@schema remoteSchemaName "the_file_outlining_schema.adama";
record OtherDoc {
private string space;
private string key;
// link the remote document to this record having
// multiple documents linked
foreign remoteSchemaName<space, key> doc;
}
table<OtherDoc> _others;
The state within the foreign document(s) would only be available to the privacy/view layer. That is, messages would not be able to interact with the foreign document, and the reason for this is that behavior would be non-deterministic. Instead, the Adama language would act as a proxy or aggregation layer that is stateful, and the document’s state would act like parameters.
This is interesting to observe because this document becomes a materialized view automatically. This is potentially problematic with privacy, but what is possible with Adama is bringing both the foreign documents’ state and compute over such that the entire thing is privacy checked per viewer.
Flow control between the aggregated document and the foreign documents would ensure that keeping this document up to date doesn’t break the bank. We can take a moment to observe that we haven’t built a query language yet, but we have manifested the internals. If this document aggregates the data that you are interested, then the key problem is the ergonomics to make that possible.
One missing piece then is indexing documents, and something that I’ve considered is adding a few indexing keywords to the language such that documents can broadcast coordinates.
public string name;
index name;
formula name_parts = name.split_whitespace();
index name_parts;
Here, a document would broadcast that the contents of the current document belong to several indices. This would enable a foreign service to provide customers the ability to find documents via parts of the document. Over time, I imagine that I’ll add something like this to Adama Platform once I commit to building the tailers. We are in fantasy land at the moment with infinite budget to handle the scope creep!
However, Adama could turn around and use these indices as well.
// the address of the remote document
private string indexed1;
private string indexed2;
// figure out how to load a schema in from the outside
@schema remoteSchemaName "the_file_outlining_schema.adama";
// link a document of the schema type to a real
// document located at (space, key) under the local name doc.
foreign<who> remoteSchemaName
USE remoteSchemaName.indexName in {indexed1, indexed2}
docs;
Here, the USE keyword acts as a signal to leverage an index which promotes the type to a list.
A tiny Boolean algebra language could be invented here to decide how local variables manifest in which documents to select.
Here we use a IN keyword to pull two indices together in an union list.
And yet, we still have yet to define a magical query language, but the building blocks are emerging such that a query planner could generate document types and code to build a standing query. This is the way.
The tension of building the query engine
Streaming is fundamentally hard because you are hooking into the write path, and you get into the relativistic problem of computing on every write regardless if there is a viewer or not. With request response, if no one asks for it, then writes are just written to disk. The problem domain makes this hard because many domains have data written once and rarely read, so results will vary. And, yet, some domains have trivial changes manifesting all the time which are zero value add to the end query.
The observation I’m making now is that thinking about efficiency from bottom-up makes the ergonomics for end users awful, so is there a world where engineers and end users work collaboratively to build efficient streams together? What I’m digging about this future Adama is that it enables engineers to aggregate things together with code producing a new document. The open question then is how to build a query language for end users which (1) generates Adama code to materialize documents, (2) manifest materialized intermediates which can be shared between queries, (3) allow engineers to define code generation rules within the query engine.
The annoying problem is how to convert existing systems into an Adama reactive document as there are many touch points, so this is where the punch to the face happens within the real world. The query language would need to be expressive enough to be convertible (and applicable) to the various SQL implementations and GraphQL.
So, look, I wrote all this, and I don’t have a strong conclusion. For that, I’m sorry as I’m thinking loudly. In terms of Adama’s future in this direction, I am definitely going to explore the tailer problem as that allows me to hook Adama into something like Kafka. I can offer a tailer kit where developers just add a function to route document changes into wherever.
Until there is a killer use-case for bringing external documents into Adama, then it doesn’t make sense to figure out how to embed a document. This is exceptionally expensive on multiple fronts! However, it’s neat, and neat things are worth considering. For now, unless a use-case or customer emerges with a down payment, this was a rambling.
As a concluding thought, I strongly believe starting with the query language first is a recipe for churn. With Adama, I’ll focus on enabling things bottom up as my bias.
- Tailers are first
- Indexing documents are a consequence of the tailer
- Foreign documents are last if there is need (and funding)