January 1st, 2022 The path towards reliability (and scale) for great sleep By Jeffrey M. Barber
As I have committed towards an open source SaaS, I am designing how to handle the failure modes since I like sleep. I’ll have much to say about the role of design on great sleep, but today I’m looking at the path towards launch and asking if there is an opportunity to provide trade-offs to the future consumer as this unfolds along with the related business model.
For clarity, each diagram here represents a single cluster within a single region under a single DNS name. I’m not sure if I want to approach multi-region design; however, I am considering what it would mean for multi-AZ design.
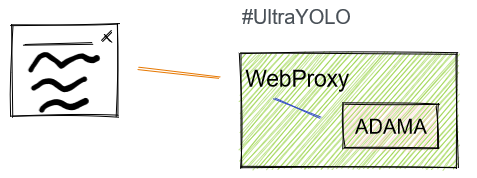
Ultra YOLO
We start with the simplest and most problematic. Take the code and then run the WebSocket frontend with Adama directly coupled within the process.
Pros
- Easy for me, a single command
- Simple to reason about
- Cheapest offering
- Lowest possible latency
Cons
- Too easy, I need to suffer more
- Not durable
- Unable to survive updates to both Web and Adama
- Reliability depends entirely on the lifetime of the host
- Scale is exceptionally limited to that single host
- Yearly data loss chance: 100%
- Easy to denial of service
Does this have legs? This could be used as an ephemeral real-time solution since it is just a state machine routable via DNS. The business here is to resell hosts on the edge, and this could work exceptionally well with something like fly.io.
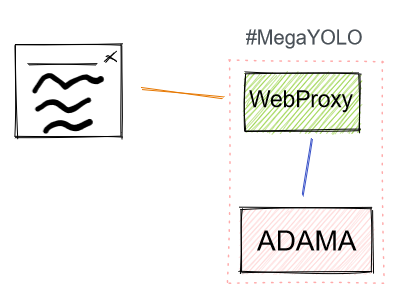
Mega YOLO
We take the Ultra YOLO and split the process with a front-end web tier connecting to an Adama host via gRPC.
Pros
- Simple to reason about
- Almost as cheap as Ultra, but the communication overhead reduces total capacity
- Still pretty quick
- Provides a natural pivot to double the scale of Ultra Yolo
Cons
- Not durable
- Unable to survive updates to Adama
- Reliability depends entirely on the lifetime of the host
- Scale is exceptionally limited to that single host
- Yearly data loss chance: 100%
- Easy to denial of service
Does this have legs? See Ultra Yolo as this is similar with minor extra costs and additional latency where the key gain is the ability to update Web instance.
Since the key failure mode would be Adama deployments, this begs the question if ephemeral real-time solution could benefit from a state hand-off protocol where a new service is stood up and then takes over the state. This would bring the data loss chance from 100% to 5% unless there is operator error. The problem with this line of thinking is that it will demand perfect operations.
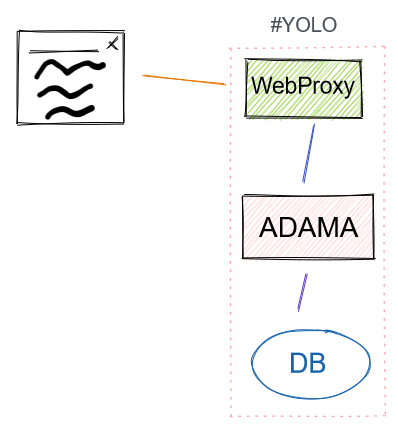
YOLO
We take the Mega YOLO and introduce a database into the mix. I’m currently using MySQL because it’s old as dirt and reliable enough.
Pros
- Simple to reason about
- Best combination of latency and pretend-responsibility
- Able to survive software updates
Cons
- Not long term durable
- Reliability depends entirely on the lifetime of the host
- Scale is exceptionally limited to that single host
- Yearly data loss chance: 5%
- Easy to denial of service
Does this have legs? It all depends on latency. The key problem is that this fakes quality with a submarine lack of durability. This will also depend on the domain, so this could be a legit option to offer people. This would be great as a small developer offering for testing.
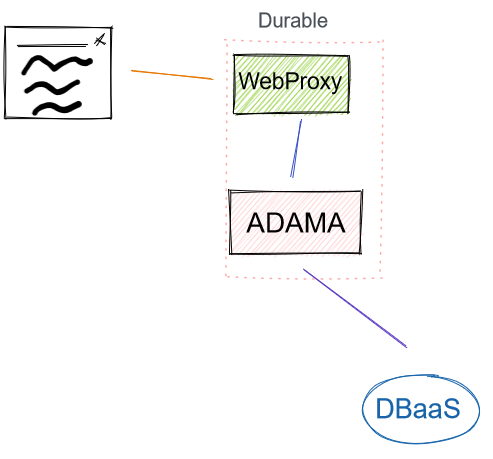
Durable
Replace managing a database with using an existing DB as a Service (i.e. RDS) which handle everything for you. The key requirement of the DBaaS is that it provides transactions within a shard holding a document’s log. The transaction is an atomic append, and this could be replaced with a raft logger as well.
Pros
- Still simple to reason about (until you build your own DBaaS)
- Durable
- Durability is handled by someone else
- Able to survive software updates
Cons
- Reliability depends entirely on the lifetime of the host
- Scale is exceptionally limited to that single host
- Easy to denial of service
- Vendor lock-in to DBaaS
Does this have legs? At this point, this can look like a “buy an Adama host” and let customers do sharding within their app (i.e. pick a DNS). I feel this is a cheat, but this is the first offering that at least feels responsible.
Defense against the interwebs
We can mitigate the denial of service by introducing multiple web proxies to front-load Adama traffic
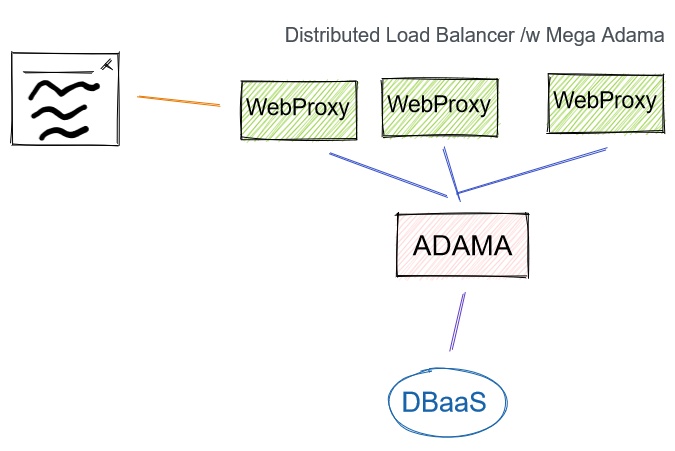
Pros
- Somewhat simple to reason about as this mirrors
- Durable
- Durability is handled by someone else
- Able to survive software updates
Cons
- Reliability depends entirely on the lifetime of the host
- Scale is exceptionally limited to that single host
- Vendor lock-in to DBaaS
Does this have legs? This extends the business of front-loading Adama’s traffic, and to some degree the business competes with cloudflare for preventing denial of service attacks. This begs the key design question of whether customers should manage their own sharding logic.
Expensive Load Balancer
Or, we can build an expensive high-throughput load balancer which can route traffic to Adama’s shard. The key aspect is that the WebProxy is just shuffling bytes between the user and Adama. Adama has several burdens like managing the document in memory, transforming messages into storage deltas, computing privacy and keeping clients up to date. Early tests on a $5/mo host indicates that memory is the key bottleneck followed by CPU.
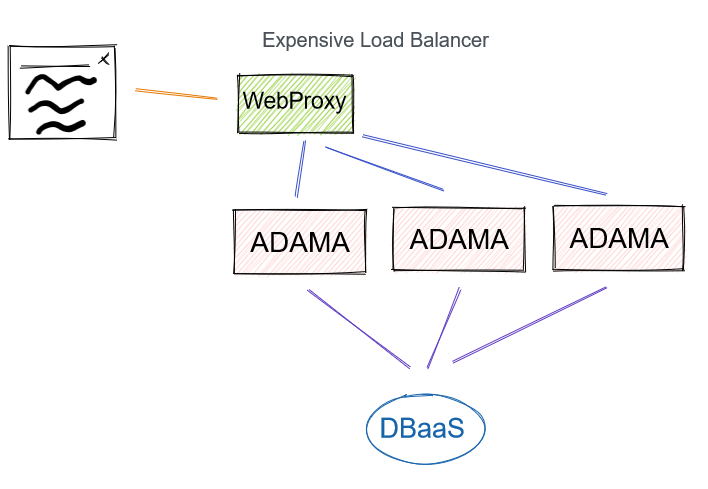
Pros
- Simple to reason about
- Durable
- Durability is handled by someone else
- Able to survive software updates
- Scales Adama up dramatically due to sharding Adama
- Reliability of Adama is managed by that expensive load balancer.
Cons
- Scale and reliability all depends on the expensive load balancer which is a single point of failure and choke point.
- Easy to denial of service
- Vendor lock-in to DBaaS
Does this have legs? This will dramatically increase scale, but the single point of failure becomes an over-promise. Fortunately, it is stateless, so recovery should be quick.
Condenser
We can combine the distributed load balancer with the expensive load balancer. We rename that single load balancer as a condenser and then optimize the protocol as it has one job: routing streams. This lets us radically simplify the expensive load balancer aspect such that it has one job. We can then offload TLS, auth, and administration based APIs to the WebProxy.
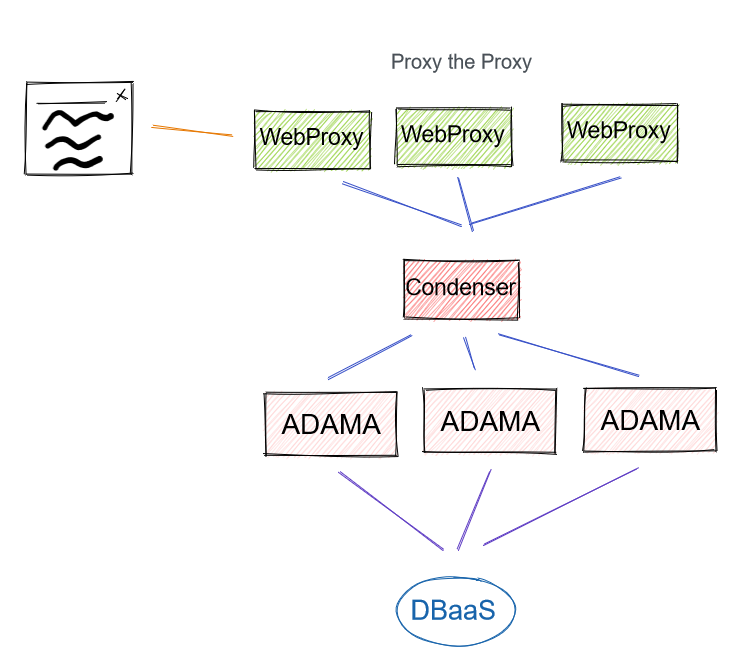
Pros
- Durable
- Durability is handled by someone else
- Able to survive software updates
- Scales Adama up dramatically due to sharding Adama
- Reliability of Adama is managed by that expensive load balancer.
- Compute offload to the WebProxy reduces condenser and Adama burden
- Static sharding could greatly increase scale and mitigate catastrophic reliability issues.
Cons
- Stack is getting longer with many pieces
- Latency is suffering multiple hops
- Scale and reliability all depends on the condenser which is a single point of failure and choke point.
- Vendor lock-in to DBaaS
Does this have legs? That single point of failure may be a deal-breaker for the unlucky customers bound to a dead condenser, but the initial web proxy fleet could be amortized across all customers and a customer could have a dedicated
Distributed Load Balancer
Fixing the reliability of the choke point is as of the same of having a distributed load balancer between the web proxy and Adama tier. This introduces an exceptionally hard routing problem between the WebProxy and Adama tier. Ideally, a document lives on exactly one Adama host. We should expect (and embrace) the possibility that two or more Adama hosts will have the same document loaded. This then forces the DBaaS to reject writes from the least up-to-date Adama host. When the not-so-up-date Adama host sees the failure, it requests a patch from the DBaaS to catch up, and it will then retry. This logic has been implemented, so progress is made. However, it comes with the burden that latency of users learning of updates depend on the frequency of every Adama host being active.
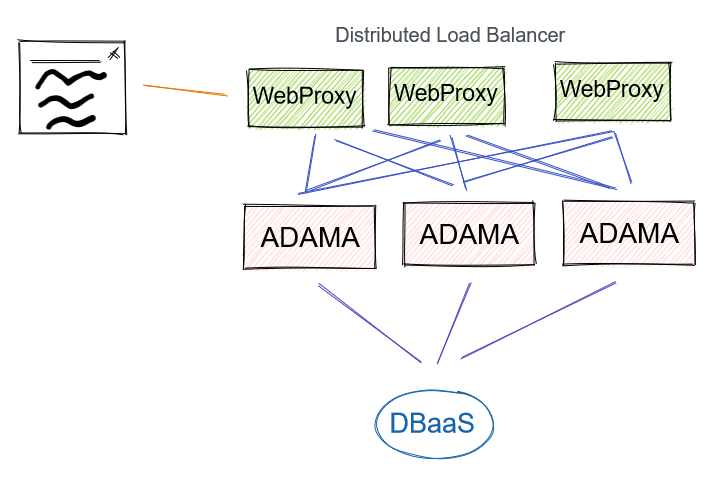
Pros
- Durable
- Durability is handled by someone else
- Able to survive software updates
- Scales Adama up dramatically due to sharding Adama
- Reliability of Adama is managed by consensus and fail-over
- Compute offload to the WebProxy reduces Adama burden
Cons
- Requires reliable failure detection
- Requires consistent routing
- Requires DBaaS to detect when routing is split
- Stack requires many new things to do all this stuff
- Latency will have more variability due to the failures induced
- Vendor lock-in to DBaaS
Does this have legs? This is potentially the best case if failure detection can be brought in cheap enough. The key gap that requires to be crossed this time is handling the failure modes of the DBaaS failing a write due to a conflict emerging from a split brain. There are a variety of fixes for this which will be discussed in a later post.
This is the model that I intend to launch with since I can leverage a gossip style failure detector to detect when capacity is added/removed and when hosts fade into the night. Since the goal of gossip is to achieve a steady state, we can then leverage rendevous hashing to bind a document to a host. The trick is that binding must be reactive such that association changes manifest in the WebProxy changing the binding. This forces retry to be located within the WebProxy.
Distributed Load Balancer plus Sharded Database
The latency of the system will depend on the DBaaS, and we can take over the DB role. Assuming we build out the DB with replicas. This will influence the design of how the WebProxy tier chooses Adama host since it doesn’t make sense to have multiple full socket meshes especially with most database clients requiring many threads to achieve concurrency.
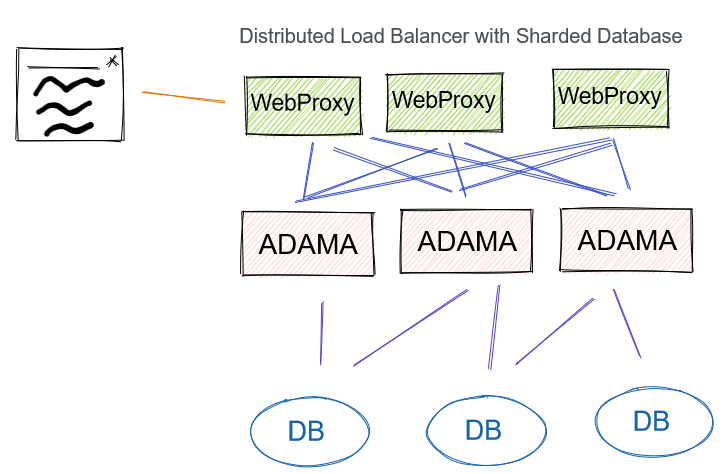
Pros
- Durable
- Able to survive software updates
- Scales Adama up dramatically due to sharding Adama
- Reliability of Adama is managed by consensus and fail-over
- Compute offload to the WebProxy reduces Adama burden
- No longer vendor locked
Cons
- Requires reliable failure detection
- Requires consistent routing
- Requires DBaaS to detect when routing is split
- Stack requires many new things to do all this stuff
- Operational burden for managing databases
Does this have legs? As of yet, I have not produced a solution that I like beyond using a DBaaS, but I suspect this will providing guidance on the protocol between WebSocket and Adama for how to do routing. Ideally, I would probably just use MySQL router or existing cluster software since this is a giant pain in the ass. The hard part of managing databases is the migration of data.
Distributed Load Balancer with Chain Replication
Let’s go wild! If the DB schema remains simple, then I could remove all the overhead and complexity of the DB and manage it by using the local file system and build my own replication schema.
I’d start with chain replication, but there are trade-offs when compared to raft/paxos. The reason I’d bias towards chain replication is that I would invent a bi-directional logger and leverage prediction.
There’s an interesting thing that happens when you think about having compute and replication live together on a chain. On one direction, you durably persist messages in a queue. This queue can be then used to flow control writes from clients. Once your messages arrive on the tail of the chain, it can be converted into a data delta and sent back on the chain. The reverse direction atomically deletes from the queue and updates state.
This has the potential to split the CPU burden between the head (for privacy computations and viewer updates) and the tail (doing work). This split allows you to optimistically update clients because the head can have a queue of messages which can be evaluated locally to turn into data updates on clients and then reverted. The state will be reconciled once durably persisted.
Pros
- Durable
- Able to survive software updates
- Scales Adama up dramatically due to sharding Adama
- Reliability of Adama is managed by consensus and fail-over
- Compute offload to the WebProxy reduces Adama burden
- No longer vendor locked
Cons
- Super complex
- Expensive on my time
- Requires reliable failure detection
- Requires a service to manage the chains
Does this have legs? Maybe as a research project. Now, it’s just too much to even think about when I can just use RDS. I need measure a bunch of things before I go off and build a new logger from scratch.
Next steps
For developers using the open source package locally, a “YOLO” box makes a ton of sense. Just configure it against a single MySQL server, and then boom.
For production, I’m thinking about how do I configure Adama with the scripts and how do deployments work. I’ve committed to building a failure detector using gossip since gossip is so cool. I’ll post updates on the design of how routing works.